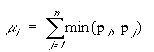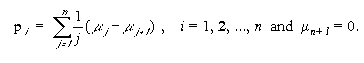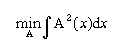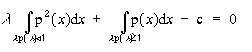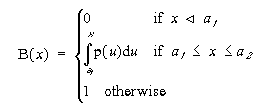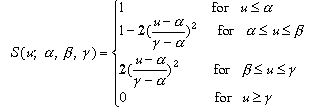
4. Possibility, Probability and Fuzzy Set Theory
Since L. Zadeh proposed the concept of fuzzy set in 1965 the relationships between probability theory and fuzzy set theory have been discussed. Both theories seem to be similar in the sense that both are concerned with some type of uncertainty and both use the interval [0, 1] for their measures as the range of their respective functions. (At least as long as one considers normalized fuzzy sets only!)
The comparison between probability theory and fuzzy set theory is difficult primarily for two reasons:
1. The comparison could be made on very different levels, that is, mathematically, semantically, linguistically, and so on.
2. Fuzzy set theory is not or is no longer uniquely defined mathematical structure, such as Boolean algebra or dual logic. It is rather a very general family of theories (consider, for instance, all the possible operations have been discussed in the previous 3 chapters, or the different types of membership functions). In this respect, fuzzy set theory could rather be compared with the different existing theories of multivalued logic. Further, there does not yet exist and probably never will exist, a unique context-independent definition of what fuzziness means. On the other hand, neither is probability theory uniquelly defined. There are different definitions and different linguistic appearances of "probability".
In recent years some specific interpretations of fuzzy set theory have been suggested. One of them, possibility theory, used to correspond, roughly speaking, to the min-max version of fuzzy set theory, that is, to fuzzy set theory in which the intersection is modeled by the min-operator and the union by the max-operator. This interpretation of possibility theory, however, is no longer correct. Rather it has been developed into a well-founded and comprehensive theory.
We shall first describe the essentials of possibility theory and then compare with other theories of uncertainty.
4.1.1. Fuzzy Sets and Possibility Distributions
Possibility theory focuses primarily on imprecision, which is intrinsic in natural languages and is assumed to be rather "possibilistic" than probabilistic. Therefore the term variable is very often used in a more linguistic sense than in strictly mathematical one. This is one reason why the terminology and the symbolism of possibility theory differs in some respects from that of fuzzy set theory. In order to facilitate the study of possibility theory, we will therefore use the common possibilistic terminology but always show the correspondence to fuzzy set theory.
Suppose, for instance, we want to consider the proposition "X is F", where X is the name of an object, a variable, or a proposition, and F is a fuzzy set. For instance, in "X is a small integer", X is the name of a variable. In "Peter is young", Peter is the name of an object. F (i.e., "small integer" or "young") is a fuzzy set characterized by its membership function F.
One of the central concepts of possibility theory is that of a possibility distribution (as opposed to a probability distribution). In order to define a possibility distribution, it is convenient first to introduce the notation of fuzzy restriction. To visualize a fuzzy restriction the reader should imagine an elastic suitcase which acts on the possible volume of its contents as a constraint. For a hardcover suitcase, the volume is a crisp number. For a soft valise, the volume of its contents depends to a certain degree on the strength that is used to stretch it. The variable in this case would be the volume of the valise; the values this variable (X) can assume different values of u is expressed by F(u). Zadeh [] defines these relationships as follows.
Definition 4-1 (fuzzy restriction): Let F be a fuzzy set of the universe U characterized by a membership function F(u). F is a fuzzy restriction on the variable X if F acts as an elastic constraint on the values that may be assigned to X, in the sense that the assignment of the values u to X has the form
X = u: F(u).
F(u) is the degree to which the constraint represented by F is satisfied when u is assigned to X. Equivalently, this implies that 1 F(u) is the degree to which the constraint has to be stretched in order to allow the assignment of the values u to the variable X.
Whether a fuzzy set can be considered as a fuzzy restriction or not obviously depends on its interpretation: This is only the case if it acts as a constraint on the values of a variable, which might take the form of a linguistic term or a classical variable.
Definition 4-2 (relational assignment equation): Let R(X) be a fuzzy restriction associated with X such as defined in definition 4-1. Then R(X) = F is called a relational assignment equation which assigns the fuzzy set F to the fuzzy restriction R(X).
Let us now assume that A(X) is an implied attribute of the variable X. For instance, A(X) = "age of Jim" and F is the fuzzy set "young". The proposition "Jim is young" (or better "the age of Jim is young") can then be expressed as R(A(X)) = F.
Example 4-1
Let p be the proposition "Peter is young" in which young is a fuzzy set of the universe U = [0, 100] chracterized by the membership function
young(u) = S(u; 20, 30, 40)
where u is the numerical age and the S-function is defined by
In this case, the implied attribute A(X) is Age(Peter) and the translation of "Peter is young" has the form
Peter is young R(Age (Peter)) = young
Zadeh related the concept of a fuzzy restriction to that of a possibility distribution as follows.
{"Consider a numerical age, say u = 28, whose grade of membership in the fuzzy set "young" is approximately 0.7. First we interpret 0.7 as the degree of compatibility of 28 with the concept labelled young. Then we postulate that the proposition "Peter is young" converts the meaning of 0.7 from the degree of compatibility of 28 with young to the degree of possibility that Peter is 28 given the proposition "Peter is young". In short, the compatibility of a value of u given "Peter is young".}[]
The concept of possibility distribution can now be defined as follows:
Definition 4-3 (possibility distribution): Let F be a fuzzy set in a universe of discourse U which is characterized by its membership function F(u), which is interpreted as the compatibility of uU with the concept labelled F.
Let X be a variable taking values in U and F act as a fuzzy restriction, R(X), associated with X. Then the proposition "X is F", which translates into R(X) = F associates a possibility distribution, x, with X which is postulated to be equal to R(X).
The possibility distribution function, x(u), characterizing the possibility distribution x is defined to be numerically equal to the membership function F(u) of F, that is,
 Where the symbol := stands for "denotes" or "is defined to be". In order to
stay in line with the common symbol of possibility theory we will denote a
possibility distribution with x.
Where the symbol := stands for "denotes" or "is defined to be". In order to
stay in line with the common symbol of possibility theory we will denote a
possibility distribution with x.
Example 4-2
Let U be the universe of integers and F be the fuzzy set of small integers defined by
F = {(1, 1), (2, 1), (3, 0.8), (4, 0.6), (5, 0.4), (6, 0.2)}
Then the proposition "X is a small integer" associates with X the possibility distribution
 in which a term such as (3, 0.8) signifies that the possibility that x
is 3, given that x is a small integer, is 0.8.
in which a term such as (3, 0.8) signifies that the possibility that x
is 3, given that x is a small integer, is 0.8.
Even though definition 4-3 does not assert that our intuition of what we mean by possibility agrees with min-max fuzzy set theory, it might help to realize their common origin. It might also make more obvious the difference betweeen possibility distribution and probability distribution.
Zadeh[] illustrates this difference by a simple but impressive example:
Example 4-3:
Consider the statement "Billy ate X eggs for breakfast". X = {1, 2, ...}. A possibility distribution as well as a probability distribution may be associated with X. The possibility distribution x(u) can be interpreted as the degree of ease with which Billy can eat u eggs while the probability distribution might have been determined by observing at breakfast for 100 days. The values of x(u) and Px(u) might be as shown in the following table:

We observe that a high degree of possibility does not imply a high degree of probability. If however, an event is not possible, it is also improbable. Thus, in way the possibility is an upper bound for the probability.
This principle is not intended as a crisp principle, from which exact probabilities or possibilities can be computed but rather as a heuristic principle, expressing the principle relationship between possibilities and probabilities.
4.1.2. Possibility and Necessity Measures
In the previous chapter a possibility measure was alredy defined (see definition 3-5) for the case that A is a crisp set. If A is a fuzzy set a more general definition of possibility measure has to be given[].
Definition 4-4 (possibility measure on a fuzzy set): Let A
be a fuzzy set in the universe of discourse U and x a
possibility distribution associated with a variable X which takes values
in U.

Example 4-4:
Let us consider the possibility distribution induced by the proposition "X is a small integer" (see examle 4-2)
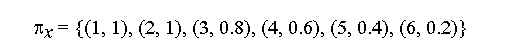
and the crisp set A = {3, 4, 5}.
The possibility measure (A) is then

If A, on the other hand, is assumed to be fuzzy set "integers which are not small", defined as
A ={(3,0.2),(4,0.4),(5,0.6),(6,0.8),(7,1),...}, then the possibility measure of "X is not a small integer" is
poss(X is not a small integer) = max {0.2, 0.4, 0.4, 0.2} = 0.4.
Fuzzy measures as defined in definition 3-1 express the degree to which a certain subset of a universe, , or an event is possible. Hence, we have
g(0) = 0 and g() = 1.
As a consequence of condition m2 of definition 3-1, that is,
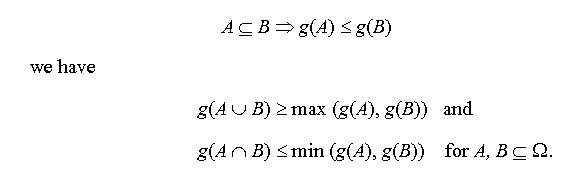
Possibility measures are defined for the limiting cases:
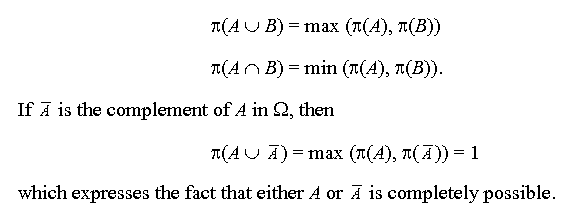
In possibility theory another additional measure is defined, which uses the conjunctive relationship and, in a sense, is dual to the possibility measure:
N is called the necessity measure. N(A) = 1
indicates that A is necessarily true (A is sure). The dual
relationship of possibility and necessity requires that
Necessity measures satisfy the condition
4.2. Probability of Fuzzy Events
By now it should have become clear that possibility is not substitute for
probability but rather another kind of uncertainty. Let us now assume that an
event is not crisply defined expect by a possibility distribution (a fuzzy set)
and that we are in classical situation of stochastic uncertainty, that is, that
the happening of this (fuzzily described) event is not certain and that we want
to express the probability of its happening. Two views on this can be adopted:
Either this probability should be a scalar (measure) or this probability can be
considered as a fuzzy set also. We shall consider both views briefly.
4.2.1. Probability of a Fuzzy Event as a Scalar
In classical probability theory an event, A, is a member of an
-field a, of subsets of a sample space . A probability measure P
is a normalized measure over a measurable space (, a) that is, P
is real-valued function which assigns to every A in a a
probability, P(A) such that
As well as, obviously, the above expression can be interpreted for continuous
case. Let is, for instance a euclidean n-space and a the -field
of Borel-sets in Rn then
If A(x) denotes the characteristic function of a crisp
set of A and Ep(A) the expectation
of A(x) then
If A(x) does not denote the characteristic function of
a crisp set but rather the membership function of a fuzzy set the basic
definition of the probability af A should not change.
Definition 4-5 (probability of a fuzzy event I.): Let
(Rn , a, P) be a probability space in
which a is the -field of Borel-sets in Rn and
P is a probability measure over Rn. Then a
fuzzy event in Rn is a fuzzy set F in
Rn whose membership function
F(x) is Borel-measurable.
The probability of a fuzzy event F is then defined by the integral:
4.2.2. Probability of a Fuzzy Event as a Fuzzy Set
In the following we shall consider sets with a finite number of
elements. Let us assume that there exists a probability measure P
defined on the set of all crisp subsets of (the universe) X the Borel
set. P(xi) shall denote the probability of element
xi X.
Let
Yager[] suggests that it is quite natural to define the probability of an
-level set as
On the basis of this the probability of a fuzzy event can be defined as
follows.
Definition 4-6 (probability of fuzzy event II.): Let A be
the -level set of a fuzzy set A representing a fuzzy event. Then the
probability of a fuzzy event can be defined as
with the interpretation "the probability of at least an degree of satisfaction
to the condition A."
The subscript Y of PY indicates that
PY is a definition of probability due to Yager which differs
from Zadeh's definition which is denoted by P. It should be very clear
that Yager considers , which is used as the degree of membership of the
probabilities P(A) in the fuzzy set
PY(A), as a kind of significance level for the
probability of a fuzzy event.
Yager also suggests another definition for the probability of a fuzzy event,
which is derived as follows:
Definition 4-7 (the truth of the proposition): The truth of the
proposition "the probability A is at leas w" is defined as the
fuzzy set P*(A) with the membership function
If we denote the complement of A by
Let us define
Definition 4-9 ("the probability of A is exactly w"): Let
Example 4-5
Let A{(x1, 1), (x2, 0.7),
(x3, 0.6), (x4, 0.2)} be a fuzzy event with
the probability defined for the generic elements: P1 = 0.1,
P2 = 0.4, P3 = 0.3, P4 =
0.2; p{x2} is 0.4, where the element
x2 belongs to the fuzzy event A with a degree of
0.7.
First we compute P*(A). We start by determining the
-level sets A for all [0, 1]. Then we compute the probability of the
crisp events A and give the intervals of w for which
P(A) w. We finally obtain P*(A)
as the respective supremum of .
The computing is summarized in the following table:
Analogously we obtain for
The probability
5. Fuzzy Logic and Approximate Reasoning
"In retraining from precision in the face of overpowering complexity, it
is natural to explore the use of what might be called linguistic
variables, that is, variables whose values are not numbers but words or
sentences in a natural or artifciial language.
The motivation for the use of words and sentences rather than numbers is that
linguistic characterizations are, in gerneral, less specific than numerical
ones." []
This quotion presents in a nutshell the motivation and justification for fuzzy
logic and approximate reasoning. Another quotation might be added, which is
much older. The philosopher B. Russel noted in his 1923 study:
"All traditional logic habitually assumes that precise symbols are being
employed. It is therefore not applicable to this terrestrial life but only to
an imagined celestal existece." []
One of the basic tools for fuzzy logic and approximate reasonong is the notion
of a linguistic variable which in 1973 was was called a variable of higher
order rather than a fuzzy variable and defined as follows []:
Definition 5-1 (linguistic variable): A linguistic variable is
characterized by a quintuple
(x, T(x), U, G, M)
in which:
x is the name of the variable;
T(x) (or simlpy T) denotes the term set of x, that
is, the set of names of linguistic values of x, with each value
being a fuzzy variable denoted generically by x and ranging over a
universe of discourse U which is associated with the base
variable u;
G is a syntactic rule (which usually has the form of a grammar)
for generating the name, X, of values of x;
M is a semantic rule for associating with each X its
meaning, M(X) which is a fuzzy subset of the universe of
discourse.
A particular X, that is a name generated by G, is called
term. It should be noted that the variable u can also be
vector-valued.
In order to facilitate the symbolism in what follows, some symbols will
have two meanings wherever clarity allows: x will denote the name of the
variable ("the label") and the generic name of its values. The same will be
true for X, and M(X).
Example 5-1
Let X be a linguistic variable with the label "Age" (i.e., the
label of this variable is "Age" and the values of it will also be called "Age")
with U = [0, 100]. Terms of this linguistic variable, which are again
fuzzy sets, could be called "old", "young", "very old", and so on. The
base-variable u is the age in years of life, M(X) is the
rule that assigns a meaning, that is, a fuzzy set, to the terms.
T(Age) will define the term set of the variable x, for instance,
in the case,
T(Age) = {old, very old, not so old, more or less young, quite young,
wery young}
where G(X) is a rule which generates the (labels of) terms in the
term set. Figure 5-1 sketches the above-mentioned relationships.
Two linguistic variables of particular interest in fuzzy logic and in (fuzzy)
probability theory are two linguistic variables "Truth" and "Probability". The
linguistic variable "Probability" is depicted in figure 5-2.
The term set of linguistic variable "Truth" might be defined by different ways.
Boldwin [] defines, for instance, some of the terms follows: (see figure 5-3)
Zadeh suggests for the term true the membership function
where v = (1+a)/2 a crossover point, and a [0, 1] is a
parameter that indicates the subjective judgment abaut the minimum value of
v in order to consider a statement as "true" at all.
The membership function of "false" is considered as the mirror image of "true",
that is
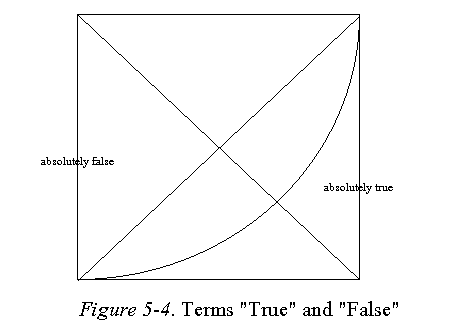
Figure 9-4 shows the above true and false terms.
Of course the membership functions of true and false, respectively, can also be
chosen from the finite universe of truth values. The term set of the linguistic
variable "Truth" is then defined as
T(Truth) = {true, not true, very true, not very true,...,false, not
false, very false,...,not very true and not very false,...}
The fuzzy sets (possibility distribution) of those terms can essentially be
determined from the term true or the term false by applying
appropriately the above-mentioned modifiers (hedges).
Definition 5-2 (stuctured linguistic variable): A linguistic
variable x is called structured if the term set T(x) and
the meaning M(x) can be characterized algorithmically. For
structured linguistic variable, M(x) and T(x) can
be regarded as algorithms which generate the terms of the term set and
associate meanings with them.
Before we illustrate this by an example we need to define what we mean by
"hedge" or "modifier".
Definition 5-3 (linguistic hedge or a modifier): A linguistic
hedge or a modifier is an operation that modifies the meaning of a term, more
generally, of a fuzzy set. If A is a fuzzy set then the modifier
m generates the (composite) term B = m(A).
Matehematical models frequently used for modifiers are:
Comcentration: con(A)(u) =
(A(u))2
Dilation: dil(A)(u) =
(A(u))1/2
contrast intensification:
Generally the following linguistic hedges (modifiers) are associated with
above-mentioned mathematical operators.
If A is a term (a fuzzy set) then
very A = con(A)
more or less A = dil(A)
plus A = A1.25
slightly A = int[plus A and not (very A)]
were "and" is interpreted possibilistically.
Example 5-2:
Let us reconsider from example 4-1 the linguistic variable "Age". The
term set shall be assumed to be
T(Age) = {old, very old, very very old...}
The term set can now be generated recursively by using the following rule
(algorithm):
Ti+1 = {old}or{very Ti} that is,
T0 = 0
T1 = {old}
T2 = {old, very old}
T3 = {old, very old, very very old}
For the semantic rule we only need to know the meaning of "old" and the meaning
of the modifier "very" in order to determine the meaning of an arbitrary term
of the term set. If one defines "very" as the concentration, then terms of the
term set of the structured linguistic variable "Age" can be determined, given
that the membership function of the term "old" is known.
Definition 5-4 (Boolean linguistic variable): A Boolean
linguistic variable is a linguistic variable whose terms, X, are Boolean
expressions in variables of the form Xp,
m(Xp) where Xp is a primari term and
m is a modifier. m(Xp) is a fuzzy set resulting
from acting with m on Xp.
Example 5-3
Let "Age" be a Boolean linguistic variable with the term set
T(Age) = {young, not young, old, not old, very young, not young and not
old young or old...}
Identifying "and" with intersection, "or" with the union, "not" with the
complementation, and "very" with the contcentration we can derive the meaning
of different terms of the term set as follows:
M(not young) = young
M(not very young) = (young)2
M(young or old) = young "or" old
...
Given the two Fuzzy sets (primary terms)
M(young) = {(u, young(u))u [0, 100]}
and
M(old) = {(u, old(u))u [0, 100]}
Then the membership function of the term "young or old" would, for
instance.
5.2.1. Classical Logics Revisited
Logics a bases for reasoning can be distingushed essentially by their three
topic-neutral (context-independent) items: truth values, vocubulary
(operators), and reasoning procedure (tautologies, syllogisms).
In Boolean Logic, truth values can be 0 (false) or (1) (true) and by means of
these truth values (operators) is defined via truth tables.
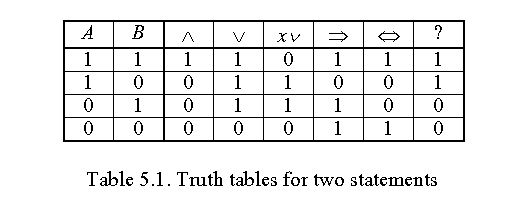
Let us consider two statements, A, and B, either of which can be
true or false, that is, have the truth value 1 or 0. We can construct the
following truth tables (where one column is one truth table of a Boolean
logical operation):
There are 16 truth tables, each defining an operator. Assigning meanings
(words) to these operators is not difficult for the first 4 or 5 columns: the
first obviously characterizes the "and", the second the "inclusive or", the
third the "exclusive or", and the fourth and fifth the implication and the
equivalence. We will have difficultie, hawever, interpreting the remaining nine
columns in terms of our language. If we have three statements rather than two,
this task of assigning meanings to truth tables becomes even more difficult.
So far it has been assumed that each statement, A and B, could
clearly be classified as true or false. If this is no longer true then
additional truth values, such as "undecided" or similar, can and have to be
introduced, which leads to the many existing systems of multivalued logic. It
is not difficult to see haw the above-mentioned problems of two-valued logic in
"calling" truth tables or operators increase as we move to multivalued logic.
For only two statements and three possible truth values there are alredy
The third topic-neutral item of logical systems is the reasoning procedure
itself which generally bases on tautologies such as
The term true is used at different places and in two defferent senses:
All but the last "true's" are material true`s, that is, they are taken as a
matter of fact, while the last "true" is a topic-neutral true. In Boolean
logic, however, these "true's" are all terated the same way []. A distinction
between a material and logical (necessary) truth is made in so called
extended logics: Modal logic [] distuinguishes between necessery and
possible truth, tense logic between statemens that were true in the past and
those that will be true in the future. Epistemic logic deals with knowledge and
belief and deontic logic with what ought to be done and what is permitted to be
true. Modal logic, in particular, might be a very good basis for applying
different measures and theories of uncertainty.
Another extension of Boolean logic is predicate calculus, which is a set
theoretic logic using quantifiers and predicates in addition to the operators
of Boolean logic.
Fuzzy logic is an extension of set theoretic multivalued logic in which the
truth values are linguistic variables (or terms of the linguistic variable
truth).
Since operators
Iv v(notA) is a point in V = [0, 1], representing the
truth value of the proposition "u is A, then the truth value of
not A is given by
v(notA) = 1- v(A)
Definition 5-5 (the truth value of v*(notA)): If
v*(A) is a normalized fuzzy set,
v*(A) = {(vi, i) i=1, ...,
n, vi [0, 1]} then by applying the extension principle,
the truth value of v*(notA) is defined as
v*(notA) = {(1 - vi, i) i=1, ...,
n, vi [0, 1]}
In particular "false" is interpreted as "not true", that is
v*(false) = {(1 - vi, i) i=1,
..., n, vi [0, 1]}
Examle 5-4
Let us consider the terms true and false, respectively,
defined as the following possibility distributions:
v*(true) = {(0.5, 0.6), (0.6, 0.7), (0.7, 0.8), (0.8, 0.9), (0.9,
1), (1, 1)}
v*(false) = v(not true) = {(0.5, 0.6), (0.4, 0.7),
(0.3, 0.8), (0.2, 0.9), (0.1, 1), (0, 1)}
then
v*(very true) = {(0.5, 0.36), (0.6, 0.49), (0.7, 0.64), (0.8,
0.81), (0.9, 1), (1, 1)}
v*(very false) = {(0.5, 0.36), (0.4, 0.49), (0.3, 0.64), (0.2,
0.81), (0.1, 1), (0, 1)}.
It has alredy been mentioned that fuzzy logic is essentially considered as an
application of possibility theory to logic. Hence the logical operators "and",
and "or", and "not" are defined accordingly.
Definition 5-5 (the four logical basic operations): For numerical
truth values v(A) and v(B) the logical operations
and, and or, not and implied are defined as
The other operators defined accordingly.
Example 5-5:
Let v*(A) = true {(0.5, 0.6), (0.6, 0.7), (0.7, 0.8),
(0.8, 0.9), (0.9, 1), (1, 1}
then
v*A = {(0, 1), (0.1, 1), (0.2, 1), (0.3, 1), (0.4, 1), (0.5, 0.4), (0.6,
0.3), (0.7, 0.2), (0.8, 0.1)}.
5.2.2. Truth Tables and Linguistic Approximation
As mentioned at the beginning of this section binary connectives (operators) in
classical two- and many-valued logics are normally defined by the tabulation of
truth values in truth tables. In fuzzy logic the number of truth values, in
general, infinite. Hence tabulation of the truth values for operators is not
possible. We can, however, tabulate truth values, that is, terms of the
linguistic variable "Truth" for a finite number of terms, such as true, not
true, very true, etc.
Zadeh [] suggests truth tables for the determination of truth values for
operators using a four-valued logic including the truth values true, false,
undecided, and unknown. "Unknown" is then interpreted as "true or falese"
(T+F).
Extending the normal Boolean logic with truth values true (1) and false (0) to
a (fuzzy) three-valued logic with a universe of truth values being two-valued
(true an false) we obtain the following truth tables where the first columns
contain the truth values for a statement A and the first rows those for
a statement B [].
Table 5-2 Truth tables for three-valued logic
If the number of truth values (terms of the linguistic variable truth)
increases one can still "tabulate" the truth table for operators by using
definition 4-6 as follows:
Let us assume, that ith row of the table represents "not true"
and the jth column "more or less true". The (i, j)th entry
in the truth table for "and" would than contain the entry for "not true more
or less true". The resulting fuzzy set would, however, most likely not
correspond to any fuzzy set assigned to the terms of the term set of "truth".
In this case one could try to find the fuzzy set of the term which is most
similar to the fuzzy set resulting from the computations. Such a term would
then be called linguistic approximation. This is an analogy to
statistics, where empirical distribution functions are often approximated by
well-known standard distribution functions.
Example 5-6:
Let V = {0, 0.1, 0.2, ..., 1} the universe,
true = {(0.8, 0.9), (0.9, 1), (1, 1)},
more or less true = {(0.6, 0.2), (0.7, 0.4), (0.8, 0.7), (0.9, 1), (1, 1)},
and
almost true = {(0.8, 0.9), (0.9, 1), (1, 0.8)}.
Let "more or less true" be the ith row and "almost true" the jth
column of the truth table "or". Then "more or less true almost true" is the
(i, j)th entry in the table:
more or less true almost true
=
{(0.6, 0.2), (0.7, 0.4), (0.8, 0.7), (0.9, 1), (1, 1)}
{(0.8, 0.9), (0.9, 1), (1, 0.8)}.
Now we can approximate the right-hand side of this equation by
true = {(0.8, 0.9), (0.9, 1), (1, 1)}
This yields
"more or less true almost true" "true".
Baldwin [] suggests another version of fuzzy logic fuzzy truth tables, and
their determination:
The truth values on which he bases his suggestions were shown graphically in
figure 9-3. They were defined as
true = {(v, true(v) = v) v [0,
1]}
false = {(v, false(v) =
1-true(v)) v [0, 1]}
very true = {(v, true(v)2 v
[0, 1]}
fairly true = {(v, true(v)1/2
v [0, 1]}
undecided = {(v, 1 v [0, 1]}
Very false and fairly false were defined correspondingly, and
absolutely true = {(v, at(v)) v [0,
1]} where
absolutely false = {(v, at(v)) v [0,
1]} where
Hence
(very)ktrue absolutely true as k
(very)kfalse absolutely false as k
(fairly)ktrue undecided as k
(fairly)kfalse undecided as k .
Using figure 5-3 and the interpretations of "and" and "or" as minimum and
maximum, respectively, the following truth table results:
"Implication statements are treated by composition of fuzzy truth value
restrictions with a Lukasewicz logic implication relation on a fuzzy truth
space. Set theoretic considerations are used to obtain fuzzy truth value
restrictions from conditional fuzzy linguistic statements using an inverse
truth functional modification procedure. Finally true functions modification is
used to obtain the final conclusion" [].
We alredy mentioned, that in traditional logic the main tools of
reasonong are tautologies such as, for instance, the modus ponens, that is
(A (A B)) B or
Premise A is true
Implication If A then B
Conclusion B is true.
A and B are statements or propositions (crisply defined) and the
B in the conditional statement is identical to the B of the
conclusion.
On the basis of what has been said in section 4.1. and 4.2., two quite obvios
generalizations of the modus ponens are:
1. To allow statements that are characterized by fuzzy sets.
2. To relax (slightly) the identity of the "B's" in the implication and
the conclusions.
This version of modus ponens is then called "generalized modus ponens" [].
Example 5-7
Let A, A', B, B' be fuzzy statements, then
the generalized modus ponens reads
Premise: x is A'
Implication: If x is A then y is B
Conclusion: y is B'.
For instance []:
Premise: This apple is very red
Implication: If an apple is red then the apple is ripe.
Conclusion: This apple is very ripe.
Zadeh suggested the compositional rule of inference for the above-mentioned of
fuzzy conditional inference []. In the meantime other other authors have
suggested different methods and investigated also the modus tollens, syllogism,
and contraposition (see []). In the frame of this textbook, however, we shall
restrict considerations to Zadeh's compositional rule of inference.
Definition 5-7 (compositional rule of inference): Let
R(x), R(x, y) and R(y),
x X, y Y, be fuzzy relations in X, X
Y, and Y respectively, (where X and Y are crisp
sets,) which act as fuzzy restrictions on x, (x, y), and
y, respectively. Let A and B denote particular fuzzy sets
in X and X Y. Then the compositional rule of inference
asserts, that the solution of the relational assigment equations (see
definition 4-1) R(x) = A and R(x, y)
= B is given by R(y) = A B, where A
B is the composition of A and B.
Example 5-8
Let the universe be X = {1, 2, 3, 4}.
A = little = {(1, 1), (2, 0.6), (3, 0.2), (4, 0)}
R = "approximately equal" be a fuzzy relation defined by
R(x) = A, R(x, y) = B, and
R(y) = A B
Applying the max-min composition for computing R(y) =
A B yields
A possible interpretation of the inference may be the following:
Premise: x is little
Implication: x and y are approximately equal
Conclusion: y is more or less little.
There are several direct applications of the approximate reasoning, for
instance, the fuzzy algorithm and fuzzy languages, however, it is not our aim
to deal with them. For more information of the above-mentioned fields see [].
5. 5. Selected Methods of Determination Memembership Functions
The problem of obtaining the values of membership function, or at least
their estimation, is of interest in the further alpplication of fuzzy set
techniques. Following a stream of fuzzy sets as formulae describing vague
notions, it is difficult to see how this problem could have a straightforward
solution. Firstly, fuzzy sets model a subjective category; therefore, their
membership functions can be evalueted in a subjective fashion. We should also
bear in mind that notations or categories modelled by fuzzy sets have a local
character, that is, to say the meaning of certain category relies upon the
context (situation) in which its application is planned. For instance, when
talking abaut a concept large steady state error in a certain community
(e.g. in control of a certain industrial system) and after establishing the
relevant membership function, it is not possible to play with the same
membership function in a completely different community; usually at least some
scaling will be necessary. From the measurement theory point of view, it is not
clear which type of scale shoul be used for estimation of the membership
function. Thole an Zimmerman [], for instance, used an absolute scale, in
Saaty's approach [], a ratio scale is suggested, while Goguen [] argues that no
stronger scale than an ordinal one may be obtained. Leaving this questions open
we focus our attention on the discussion of some methods that may be used in
engineering practice when the membership function has to be estimated.
A straightforward method for estimating the values of the membership function,
whose roots form the example cited by Borel, can be compactly stated as
follows.
Consider a group of researchers (experts) involved with the same area of
investigation. They are asked to answer a question having a format:
Can x0 be viewed as compatible with the concept represented
by the fuzzy set A?
where x0 is a fixed element of the universe of discourse. The
answer is "yes" or "no". Then, counting the fraction of positive ("yes")
response n(x0) found in the total number of
responses,
we get the value of the membership funcion of this element of the universe of
discourse x0
with N being the total number of responses dealt with x0.
Moreover, following this statistical approach, one can also determine a
confidence interval at a prespecified level of probability. Denote the obtained
bounds by x0
5.5.2. "Pairwise comparison" method
The membersip function expressed on a ratio scale can be conveniently
estimated by a pairwise comparison as proposed in the []. As usual,
i denotes the degree to which the ith element of the
universe of discourse fulfils the fuzzy notion A. Take, now, the ratios
i/j for all i, j = 1, 2, ...,
n and arrange them in the form of square matrix
[i/j]. Multiplying it by a vector
i = [1, 2, ...,
n], we get a system of equations
[i/j] = n
i.e.
([i/j] - n) = 0.
Thus, 'n' forms the largest eigenvalue of the above eigenvalue problem (the
remainder are equal to zero), and is the corresponding eigenvector.
An experiment performed using the idea that stems from the above finding relies
on obtaining estimates of these grades by making pairwise comparison of the
elements of the universe of discourse. Assuming a certain scale in which this
comparison is realized (usually consisting of abaut 7 grades), a researcher is
asked to evaluate the ith element of the universe of discourse with
respect to the jth one. The more preferable the ith element is
with respect to the jth one, the closer the value of the (i,
j)th element of the matrix A to the highest value in the scale
established. Conversely, if the ith element is completely rejected with
respect to the jth one, the estimated value of A is equal to the
reciprocal of the highest value of the scale. Also, for each element lying
onthe diagonal of A, we write 1.0. Summarising after performing all
pairwise comparisons, a matrix A is given. Obviously, now, only an
approximate equality might be expected, namely
aij = i/j
and the transitivity property is no longer preserved (i.e.
aikakj aij).
There are some numerical schemes useful for the calculation of the membership
function on the basis of matrix A. One of them, [], takes the problem of
minimisation of a sum of squares
subject to constraints
Then, renormalising i's in such a fashion that the maximal
value of is equal ti 1, we get the membership function of a normal fuzzy
set.
5.5.3. "Probabilistic characteristics" method
In the methods described so far, the membership function was calculated
with the aid of a probability function obtained by the previous experiment. In
[], a bijective mapping, turning a probability function into a membership
function and vica versa, has been introduced. For the discrete probabilities
p1, p2, ..., pn,
pi = 1, arranged in descending order p1
p2 ... pn, the values of the membership
function 1, 2, ..., n
are computed by the formula
Setting 1 = 1, or noticing the normalisation condition, one
also has
Not assuming any arrangement of pi's, one has
By inspection, the membership function and the corresponding probability
function have the same shape. Therefore, i =
j implies pi = pj
and, from i j, we know that
pi pj. Solving (1) with respect to
pj for j known, we get
In [], a continuous case has been investigatid. Given a probability density
function (PDF) defined in R, the corresponding membership function is
calculated to minimise a performance index
subject to the following constraints:
(i) E(A(x)) x is distributed according to the PDF c
Where E() stands for the expected value of the membership function of A while
'c' denotes a confidence level put close to 1.
(ii) 0 A(x) 1.
An integral in the above formulation, which is minimised, visualises the fact
that the obtained membership function, A, is 'sharp' (i.e. selective) enough
(in the sense of the energy measure of fuzziness). Between the two constraints,
the second one is obvious, while the first states the fact that the elements
which are most likely (in the sense of probability) should have high membership
values.
By the use of constrained optimisation techniques for infinite dimensional
space, the optimal membership function is equal to
with resulting from the following equation
Treating a fuzzy set as a projectable random set can be fruitful in determining
a membership function following such a contsruction. When describing vague
notions, it is evident that the most difficult situation is to express a grade
of membership for intermediate elements, not for those which completely belong
or do not belong to the concept (satisfy it).
Let us consider regions between two such fuzzy notions (for example, modelling
a concept of high and medium) where uncertainty of classification
of these objects to one of the categories is significant. Suppose it can be
characterised by means of the probability density function p(x). This
function can be estimated, for instance, by making use of histogram of
responses 'don't know'. Assume p(x) takes non-zero values in a certain
closed interval of the space in which the fuzzy sets are defined. Then the
membership functions of A and B, say medium and high, are
constructed accordingly (see Figure 5-1):
and
Some relations of the problem of membership function estimation to psychometric
scaling techniques discussed by Thurstone [] has been discussed in [].
The first chapter has contained the main ideas of fuzzy sets, giving the
reader a concise presentation of fundamentals of their theory. The reader can
get an overall view of some techniques that are characteristic for fuzzy set,
has inspected some fuzzy set theoretic operations, some techniques of fuzzy
measures and measures of fuzzyness, the possibility and probability theory.
After this the progressively growing field of fuzzy logic and approximate
reasoning have been introduced.
A reader who wishes to become involved in greater detail concerning fuzzy sets
can refer to existing literature.
References
[1] Zadeh, L. A. 1965. Fuzzy sets. Information & Control, vol 8,
338-353.
[2] Zadeh, L. A. 1965. Fuzzy sets and systems Proc. Symp. on System Theory,
Polytech. Inst. Brooklyn, 29-37.
[3] Godal, R.C., and T.J. Goodman 1980. Fuzzy sets and borel. IEEE Trans. on
System Man, and Cybernetics, vol 10, 637.
[4] Bellman, R. and M. Giertz 1973. On the analitic formalism of the theory of
fuzzy sets. Information Sciences vol 5, 149-156.
[5] Bonissone, P.P., and K.S. Decker 1986. Selecting uncertainty calculi and
granularity: An experiment in trading-off precision and complexity. In Kanal
and Lemmer. 217-247.
[6] Dubois, D., and H. Prade 1985. A review of fuzzy set aggregation
connectives. Information Science 36, 85-121.
[7] Mizumot, M. 1989. Pictorial representations of fuzzy connectives, Part I:
cases of T-norms, T-conorms and averaging operators. FSS 31, 217-242.
[8] Dubois, D., and H. Prade 1980. New results abaut properties and semantics
of fuzzy set- theoretic operators. In Wang and Chang, 59-75.
[9] Dubois, D., and H. Prade 1982. A class of fuzzy measures based on
triangular norms. Inter. J. Gen. Syst. 8, 43-61.
[10] Thole, U., H.J. Zimmermann, and P. Zysno, 1979. On the suitability of
minimum and product operators for the intersection of fuzzy sets. FSS
2, 167-180.
[11] Werners, B. 1984. Interaktive Entscheidungsunterstutzung durch ein
flexibles mathematisches Programmierungsytem. Munchen.
[12] H.J. Zimmermann, H.J., and P. Zysno, 1983. Decision and evaluations by
hierarchical aggregation of information. FSS 10, 243-266.
[13] Werners, B. 1988. Aggregation models in mathematical programming. In
Mitra, 259-319.
[14] H.J. Zimmermann, H.J., and P. Zysno, 1980. Latent connectivities in human
decision making. FSS 4, 37-51.
[15] Klir, G.J., and T.A. Folger 1988. Fuzzy Sets, Uncertainty and Information.
Englewood Cliffs.
[16] Sugeno, m. 1977. Fuzzy measures and fuzzy integralsA survey. In Gupta,
Saridis, and Gaines. 89-102.
[17] Murofushi, T., and M. Sugeno, 1989. An interpretation of fuzzy measures
and the choquet integral as an integral with respect to a fuzzy measure.
FSS 29, 201-227.
[18] Dubois, D., and H. Prade, 1988. Possibility Theory. Plenum Press, New
York.
[19]
[20]
[21]
[22]
[]
[]

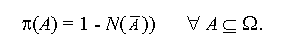
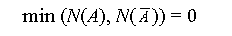 The reationships between possibility measures and necessity measures satisfy
also the following conditions[]:
The reationships between possibility measures and necessity measures satisfy
also the following conditions[]:

 the probability of A can be expressed as
the probability of A can be expressed as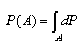
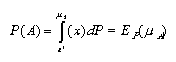

 be a fuzzy
set representing a fuzzy event. The degree of
membership of element xi A is denoted by
A(xi). -level sets or -cuts such as alredy
defined in definition 1-4 shall be denoted by A.
be a fuzzy
set representing a fuzzy event. The degree of
membership of element xi A is denoted by
A(xi). -level sets or -cuts such as alredy
defined in definition 1-4 shall be denoted by A.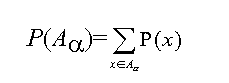

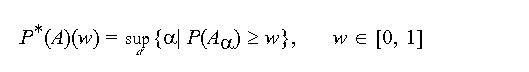 We should realize, that now the "indicator" of significance of the probability
measure is w and no longer . We should also be aware of the fact that we
have used Yager's terminology denoting the values of the membership function by
P*(A)(w). This will facilitate reading Yager`s
work[].
We should realize, that now the "indicator" of significance of the probability
measure is w and no longer . We should also be aware of the fact that we
have used Yager's terminology denoting the values of the membership function by
P*(A)(w). This will facilitate reading Yager`s
work[]. can be interpreted as the truth of the
proposition the "probability of A is at least w".
can be interpreted as the truth of the
proposition the "probability of A is at least w". If
If  (A)(w)
is interpreted as the truth of the proposition "probability of A is at
most w", then we can argue as follows: The "and" combination of the
"probability of A is at least w" and the "probability of A
is at most w" might be considered as "probability of A is exactly
w". If
(A)(w)
is interpreted as the truth of the proposition "probability of A is at
most w", then we can argue as follows: The "and" combination of the
"probability of A is at least w" and the "probability of A
is at most w" might be considered as "probability of A is exactly
w". If  are considered as possibility distributions then their conjunction is their
intersection (modeled by applying the min-operator to the respective membership
functions). Hence the following definition:
are considered as possibility distributions then their conjunction is their
intersection (modeled by applying the min-operator to the respective membership
functions). Hence the following definition: be defined as above. The possibility distribution associated with the
proposition "probability of A is exactly w" can be defined as
be defined as above. The possibility distribution associated with the
proposition "probability of A is exactly w" can be defined as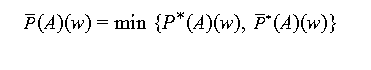

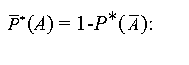

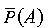 (A)of the fuzzy event A is now determined by the intersection of the fuzzy
sets P*(A) and
(A)of the fuzzy event A is now determined by the intersection of the fuzzy
sets P*(A) and
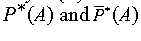 modeled by the min-operator as in definition 4-7:
modeled by the min-operator as in definition 4-7:
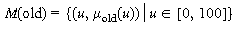

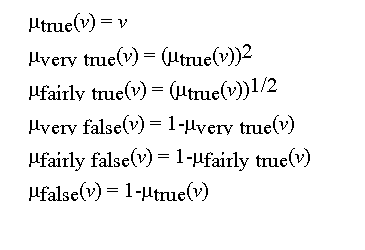

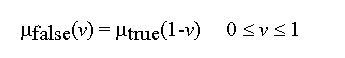

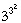 = 729 truth tables! The uniqueness of interpretation of truth tables, which is
so convenient in Boolean logic, disappears immediately because many truth
tables in three-valued logic look very much alike.
= 729 truth tables! The uniqueness of interpretation of truth tables, which is
so convenient in Boolean logic, disappears immediately because many truth
tables in three-valued logic look very much alike. A
A in fuzzy logic are also defined by using truth tables,
the extension principle can be applied to derive definitions of the operators.
So far, possibility theory has primary been used in order to define operators
in fuzzy logic, even though other operators have also been investigated [], and
could also be used. In this book we will limit considerations to possibilistic
interpretations of linguistic variables and we will also stick to the original
proposals of Zadeh []. To the interested reader several supplemental study of
alternative approaches can be found in the [].
in fuzzy logic are also defined by using truth tables,
the extension principle can be applied to derive definitions of the operators.
So far, possibility theory has primary been used in order to define operators
in fuzzy logic, even though other operators have also been investigated [], and
could also be used. In this book we will limit considerations to possibilistic
interpretations of linguistic variables and we will also stick to the original
proposals of Zadeh []. To the interested reader several supplemental study of
alternative approaches can be found in the [].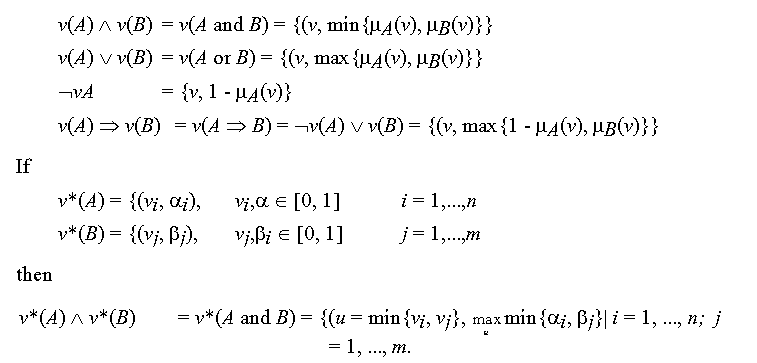
T F T+F
T T F T+F
F F F F
T+F T+F F T+F
"and
"
T F T+F
T T T T
F T F T+F
T+F T T+F T+F
"or"
T F
F T
T+F T+F
"not"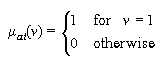

v(P) v(Q) v(P and Q) v(P or Q)
false false false false
true false false true
true true true true
undecided false false undecided
undecided true undecided true
undecided undecided undecided undecided
true very true true very true
true fairly true fairly true true
Some
more considerations and assumptions are needed to derive the truth table for
the implication. Baldwin considers his fuzzy logic to rest on two pillars: the
denumerably infinite multivalued logic system of Lukasewicz logic and fuzzy
theory.
1 2 3 4
1 1 0.5 0 0
R: 2 0.5 1 0.5 0
3 0 0.5 1 0.5
4 0 0 0.5 1
For
the formal inference denote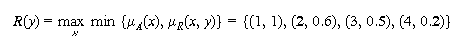
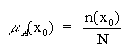
 respectively, Thus, in fact an appropriate interpretation of the result enables
us to evaluate the precision of the membership obtained. This method for
determining the membership function is mentioned in [] and [], however, no
method for expressing its precision is provided.
respectively, Thus, in fact an appropriate interpretation of the result enables
us to evaluate the precision of the membership obtained. This method for
determining the membership function is mentioned in [] and [], however, no
method for expressing its precision is provided.
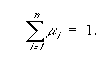
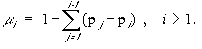 (1)
(1)