 Laszlo Czap
Laszlo Czap



Page 1
LIP REPRESENTATION BY IMAGE ELLIPSELászló CzapUniversity of Miskolc, Department of AutomationH 3515 Miskolc, EgyetemvárosE-mail: czap@malacka.iit.uni-miskolc.huABSTRACTAutomatic speechreading systems through their use of visualinformation to support the acoustic signal have been shown toyield better recognition performance than purely acousticsystems, especially when background noise is present. In thispaper an answer is sought to the most important questions ofspeechreading: Which features can represent visual informationwell? How can they be extracted? Well-known geometricmoments are discussed as a means of visual speechrepresentation. Proposed image ellipse axes are shown to berobust and computationally simple features for describing theshape of lips. An intelligibility study was carried out to seewhich part of the face gives the most support to speechreading.The whole face, mouth or lips were visible dubbed with noisyvoice. Visual support to speech perception of the image ellipsemodel is compared to that of the parts of the natural face.1. INTRODUCTIONNowadays we are witnesses of the enormous development ofspeech recognition by machines. They, however, still performpoorly when background noise is present. It is generally agreedthat most visual information is carried by the lips. The inner lipsare especially important and some minor improvement comesfrom the visibility of teeth and tongue. The main difficulty ofincorporating visual information into an acoustic recogniser is tofind a robust and accurate method for extracting visual speechfeatures. These features should be sensitive to lip movement andinvariant for translation, rotation and scale. Several studies haveshown that combining visual information with acousticalinformation can improve the performance of both the humanperceiver and the automatic recogniser. All those studies haveshown that audio-visual recognition scores are always higherthan either the audio or visual ones in all conditions. This is thegreatest challenge and the most important objective for bimodalintegration.2. VIDEO PROCESSINGVideo processing aims at pre-processing a sequence of imagesand extract features suitable for recognition. Because the systemshould be acceptable to the speaker, no special illumination andface position constraint were applied. Conventional make up –red lipstick – is acceptable to female speakers. The variabilityproblem of lip colour estimation is partially solved by redlipstick in this study. To find the region of interest in a fullcolour image hue of the HSB colour space is a very suitablefeature. Skin hue is constant across talkers and even across racesdespite the fact that lightness can vary significantly. [1, 2] Tofind the lip the saturation of the same colour space is also robustto illumination conditions. Video pre-processing is related to thefeature extraction. A few lip models require finding the lipcontours. The system under discussion – as we will see later on– is robust to inaccurate thresholds.2.1 Feature extractionMuch of the research in speechreading systems is focused on thecrucial problem of feature extraction. How can it best transforma sequence of images into feature values that facilitaterecognition? The process should be fast, robust, and yield asmuch information as possible carried by the fewest number offeatures, removing redundant and linguistically irrelevantinformation. Whereas there is no one favourite way ofrepresenting visual speech there are impressive methods such asdynamic contours [3], manifolds [4], deformable templates [5],and active shape models [6] that have been and are beingdeveloped.Moment functions [7, 8] have a broad spectrum of imageanalysis such as invariant pattern recognition and objectclassification. A set of moments computed from a digital imagegenerally represents global characteristics of the image shape andprovides lots of information about different types of geometricalfeatures of the image. Functions of geometric moments can beinvariant with respect to image plane transformations such astranslation, rotation and scale. Geometric moments were the firstones applied to image processing as they are computationallyvery simple.Two dimensional geometric moments of (p+q)th order aredefined as,),(dxdyyxfyxmqppq∫∫=ζp,q=0,1,2,3....where denotes the image region of the x-y plane, which is thedomain of the intensity function f(x,y).Geometric moments of different orders represent differentspatial characteristics of the image intensity distribution. A setof moments can thus form a global shape descriptor of an image.Physical interpretation of some geometric moments: Bydefinition, the moment of order zero (m00) represents the total
Page 2
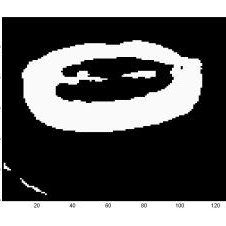
intensity of an image. First order functions (m01 , m10) provideintensity moments about the x and y axis, respectively. Theintensity centroid (x0 , y0) is given byx0 = m10/m00 ; y0 = m01/m00It is convenient to evaluate moments with the origin of thereference system shifted to the intensity centroid of the image.This transformation makes moments independent of theposition of the object. Moments computed with respect to theintensity centroid are central moments and defined as,),()()(00dxdyyxfyyxxqppq−∫∫−=ζμp,q=0,1,2,3....Second order moments are a measure of variance of the imageintensity distribution about the origin. Central moments 20 and 02 give the variances about the mean. The covariance measure isgiven by 11.Second order central moments can be thought to be the momentsof inertia of the image about a set of reference axes parallel to theimage coordinate axes and passing through the intensity centroid.Principal axes of inertia of the image are defined as the set of twoorthogonal lines through the image centroid being used as areference system. Moments of inertia ( 20, 02) of the imageabout this reference system are then called principal moments ofinertia of the image. If 20, 02and 11 are the second ordercentral moments of an image in its actual image reference frameand if I1 , I2 refer to its principal moment of inertia values, then,2]4)[()(2/12112022002201μμμμμ+−++=Iand.2]4)[()(2/12112022002202μμμμμ+−−+=IThese equations can be used to define an image ellipse, whichhas the same moments of inertia as the original image. Lengths a,b of semi-major axis and semi-minor axis of the image ellipse aregiven bya = 2 (I1/ 00)1/2 ; b = 2 (I2/ 00)1/2.The orientation angle of one of the principal axes of inertiawith the x-axis is given by the following equation:−=Θ−0220111221μμμtanThe image ellipse also has a uniform intensity value k inside andzero outside preserving the value of the zero order momentdefining the intensity factor)/(00abkπμ=.The intensity factor k for the oral cavity carries information onthe visibility of the teeth and tongue. An image ellipse cantherefore characterise fundamental shape features of an object.The term s = (I1+I2)/m00 is sometimes called shape spreadness,and the term e = (I2 – I1)/(I2 + I1) is called shape elongation.abFigure 1. Lip shapes extracted with different thresholdsproviding a=55, b=35 and a=58, b=35 semi-major and semi-minor axes in pixels, respectively.One of the requirements of feature extraction is to be robust tothe variations of lighting and other conditions. The image ellipsemodel does not require finding the lip contours, and its featuresare robust to the thresholds of video pre-processing (Figure 1.).Figure 1. a shows a binary image with a high threshold (lipcorners are fallen to background) while in Figure 1. b. thethreshold is too low, (a part of the tongue and chin contour isconsidered to belong to the lip). In spite of the difference in thebinary image, the extracted geometric features are only slightlydifferent.Whereas parameterisation of acoustic data is well established, itis not well known which visual features carry the most relevantspeech information and which models of the image are mostsuitable for automatic speechreading.Figure 2 shows the ellipses of the inner and outer boundaries ofthe lips applied to the binary image after video processing. Thealgorithm was developed under MATLAB and was applied to2685 image frames for experiment discussed in next paragraph.
Page 3
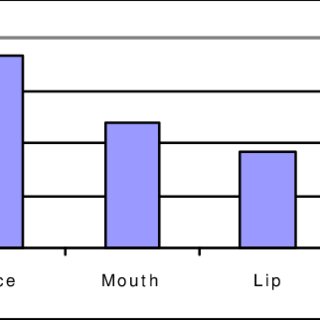
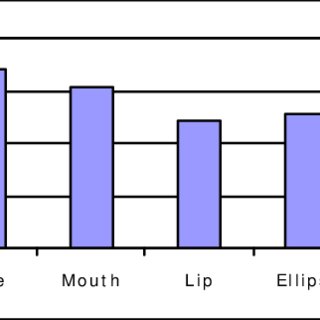
Figure 2. Image ellipses of the inner and outer lip boundariesduring the utterance of ‘a’ (O*) and ‘u’ (u*) (*SAMPA codesof the vowels).2.2. An intelligibility studyTo find out which parts of the face give more information to ahuman perceiver an intelligibility study (experiment 1.) wascarried out. The corpus was a series of V1CV1 words with aconsonant between the same vowels. (e.g., ete, ama) and a seriesof C1VC1 words with a vowel between the same consonants.(e.g., bob, tet). The series of consonants and vowels in themiddle covered all Hungarian phonemes.The first stage of our bimodal recognition research aimed atgetting information on the visual support of different parts ofthe face compared to the ellipse model. In the test series thesubjects were 78 university students without prior phoneticstudy. They were asked to listen to the same word twice. Thenthey wrote down the consonant or the vowel in question. Theyhad limited time for the answer (3 seconds). They were listeningto the voice of a series of words each containing the words withonly acoustic stimulus then an other series supported with theimage sequence of the speaker's lips, then with her mouth (lips,teeth and tongue), then with the whole face. To see the usabilityof the 2D lip model derived from the image ellipse (filling thearea between the two ellipses of Fig. 2 with red), one of thestimuli was an ellipse shown dubbed with noisy voice. Subjectswatched the image on the same TV monitor and listened to thevoice from a loudspeaker. A clear acoustic stimulus does notneed any visual support for recognition. To see theimprovement of recognition, the acoustic signal was degraded byadditive white noise. The momentary signal to noise ratio wasfixed in every 5 milliseconds to -6 dB SNR for consonant and –18dB for vowel experiments. The reason for using momentarySNR was to avoid disturbing consonants more than vowels byan average level of noise. The noise level was calculated to keepthe desired signal to noise ratio all the time. There was also anexperiment carried out with only the visual stimulus.Results were obtained after evaluating 11,623 answers. 9,625 ofthem were to serve consonant recognition and 1,998 of themwere used for vowel recognition.Figures 3, 4, 5 show the results of the intelligibility study ofdifferent stimuli.Figure 3.. Rate of the correct answers of the VCV words(consonant recognition), after watching a part of the face (orsynthetic lips) and listening to a –6 dB SNR acoustic stimulus.Figure 4. Rate of the correct answers of the VCV words(consonant recognition), by watching a part of the face (orsynthetic lips) without any acoustic stimulus.010203040FaceMouthLipEllipseAudio% of correct recognition05101520FaceMouthLipEllipse% of correct recognition
Page 4
Figure 5. Rate of the correct answers of the CVC words (vowelrecognition), through watching a part of the face (or syntheticlips) and listening to a –18 dB SNR acoustic stimulus.It is not surprising that the whole face contains relevantinformation to perceive speech. The less part of the face wereshown, the fewer words were recognised correctly. Although the2D ellipse representation of the lips is uncommon, the subjectsaccepted it. Results of the different stimuli show an error rate ofthe synthesised stimulus comparable to that of natural lips.These results and the robustness of axis of the image ellipse areencouraging for us to use them as visual features of aspeechreading system. To be able to get information on thebrightness of the oral cavity (teeth and tongue either visible ornot), the intensity factor k was added to the a and b axes of theellipse of the inner lips. This aims at improving the recognitionrate of the ellipse model towards that of a visible mouth.In the automatic recognition experiment the corpus ofspeechreading was the manually segmented 120 ms speech ofthe middle of C1VC1 words. (C is selected from b, v, t, l, j and k,while V is selected from a (O), á (a:), e (E), é (e:), i (i), o (o), ö(2), u (u) and ü (y).) The aim of recognition is to identify thevowel, taking the sequence of three images from the manuallysegmented middle of the vowel (key-frames). Axes a and b andthe intensity factor k - calculated for the intensity of oral cavity- were the features of the visual signal. (Visual featuresspreadness s, elongation e, and intensity factor k were also triedand provided the same results as the previous ones.) Five seriesof 54 CVC words (six of C by nine of V) were pronounced by afemale speaker. Three of the five utterances were used fortraining and two of them for testing. Training patterns wereexcluded from testing.A feed-forward neural network was trained by a backpropagation algorithm with visual signals. There were 18patterns (six surrounding consonants by three utterances) usedfor training and 12 patterns (two utterances) were used fortesting for each of the nine vowels. The 18 training patternswere represented by three neurons in the hidden layer for eachvowel. A feed-forward neural network was trained by conjugategradient back propagation algorithm with Powell-Beale restartsduring 2.000 epochs (MATLAB implementation). A recognitionrate of 81% was obtained for visual stimuli.3. CONCLUSIONSIn this paper geometric moments are proposed for lip shapedescriptors. An image ellipse can be derived from second ordermoments that can represent the shape, orientation and positionof the lips. An intensity factor represents the visibility of teethand tongue. Using these features, an 81% recognition rate wasreached in a vowel recognition task using visual features by anautomatic recogniser. Human perceivers on 75 VCV and 27 CVCwords, the subjects judged the consonant or the vowel in themiddle of the word evaluated the proposed method. Therecognition rate was comparable for natural lips and thesynthesised 2D image ellipse lip model. Semi-syllables are thekey structures in Hungarian continuous speech recognition [9]and this work is going to be further developed for the Hungariancontinuous audio-visual speech recognition.. REFERENCES1. Massaro, D.W., Stork, D.G., Speech recognition andsensory integration, American Scientist, May-June, 1998.2. Nankaku, Y., Tokuda, K., and Kitamura, T. Intensity-and location normalised training for HMM-based visualspeech recognition. In Proceedings of the Eurospeech’99,Budapest: pp. 1287-1290, 1999.3. Petajan, E.D. Automatic lipreading to enhance speechrecognition. In Proceedings of the GlobalTelecommunications Conference, Atlanta, GA: IEEECommunication Society. pp. 265-272, 1984.4. Bregler C., and Omohundro, S.M. Nonlinear imageinterpolation using manifold learning. In G. Tesauro,D.S. Touretzky and T.K. Leen (Eds.), Advances inNeural Information Processing Systems, vol. 7,Cambridge, MA: MIT Press. pp. 973-980, 1995.5. Yuille, A.L., Cohen D.S., and Hallinan, P.W. FeatureExtraction from Faces Using Deformable Templates. InProceedings of the Computer Vision and PatternRecognition. Washington, DC. IEEE Computer SocietyPress: pp. 104-109, 1989.6. Luettin, J., Thacker N.A., and Beet, S.W. Active shapemodels for visual speech feature extraction. In D.G.Stork and M.E. Hennecke (Eds.), Speechreading byHumans and Machines, Berlin: Springer-Verlag, pp. 383-390, 1996.7. Hu, M.K. Visual pattern recognition by momentinvariants. IRE Transactions on Information Theory,Vol. 8. (1) pp. 179-187, 1962.8. Mukundan, R., and Ramakrishnan K.R. Momentfunctions in image analysis. Singapore: Word ScientificPress. pp. 11-24, 1998.9. Vicsi, K., Vigh, A. Text independent neural network/rulebased hybrid, continuous speech recognition.EUROSPEECH’95. Madrid: pp. 2201-2204, 1995.020406080FaceMouthLipEllipseAudio% of correct recognition


